在本节中,将介绍几种经典的分布式并行范式,包括流水线并行(Pipeline Parallelism),数据并行(Data Parallelism)和张量并行(Tensor Parallesim)。微软开源的分布式训练框DeepSeed,融合了这三种并行范式,开发出3D并行的框架,实现了千亿级别模型参数的训练。
模型分层部署为PP,维护相同参数量为DP,张量拆分为TP
流水线并行PP
当模型太大,一块GPU放不下时,流水线并行将模型的不同层放到不同的GPU上,通过切割mini-batch实现对训练数据的流水线处理,提升GPU计算通讯比。同时通过re-materialization机制降低显存消耗。
详细的讲解在https://zhuanlan.zhihu.com/p/613196255,这里记录了一些其中不理解的地方
“bubble部分的时间复杂度为O((K-1)/K)”时间复杂度的解释
在计算机科学中,“时间复杂度”通常用来描述算法运行时间随输入规模增长的趋势(如 )。
但在这篇笔记及并行计算的语境下,这个“时间复杂度”的定义略有不同。它指的不是算法跑了多少步,而是 “系统资源浪费(空泡)的比例随 GPU 数量 的变化趋势”。更准确地说,这里计算的是 空泡率(Bubble Ratio)。
在流水线并行(Pipeline Parallelism)中,我们关心核心指标是效率(Efficiency)。
- 定义核心:衡量由于流水线设计导致的**闲置时间(Idle Time)占总运行时间(Total Time)**的比例。
- 公式化定义:
几个Batch的区别
- 详细解释
(1) Batch (通常指 Mini-batch)
在日常口语和大多数代码中,当我们说 “Batch” 时,实际上指的都是 Mini-batch。
- 定义:这是模型进行**一次参数更新(Optimizer Step)**所使用的全部数据量。
- 关键点:神经网络的训练是基于随机梯度下降(SGD)的。为了让模型学到东西,我们不能看一张图就改一次参数(太震荡),也不能看完所有数据才改一次(太慢)。我们取一小堆数据,算出它们的平均梯度,然后更新一次模型权重。这一堆数据就是 Mini-batch。
- 在大模型中:这个概念通常被称为 Global Batch Size。
(2) Batch Size
- 定义:这是一个标量数值(Number),表示一个 Batch(Mini-batch)里包含多少个样本。
- 例子:如果你有 1000 张图片,你设置 Batch Size = 32。意味着模型每次会并行处理 32 张图,计算这 32 张图的损失总和,然后更新权重。
(3) Micro-batch (微批) —— 流水线并行的核心
- 背景:在大模型训练中,单个 Mini-batch(比如 512 个样本)可能非常大,大到显存塞不下;或者如上图所示,如果一次性把整个 Mini-batch 塞进流水线,会导致巨大的 Bubble(空泡/等待时间)。
- 定义:Micro-batch 是将 Mini-batch 进一步切分后的更小单元。
- 操作逻辑:
- 我们不直接把整个 Mini-batch 丢进网络。
- 我们将它切分成 个 Micro-batches。
- 前向/反向传播(Forward/Backward) 是以 Micro-batch 为单位在各个 GPU 之间流转的(看图中的 )(其中,第一个数字角标代表第几块GPU,第二个数字角标代表第几个Micro-batch)。
- 梯度累积(Gradient Accumulation):每个 Micro-batch 算出的梯度不会立刻用来更新权重,而是先暂存(累加)起来。
- 参数更新:直到属于同一个 Mini-batch 的所有 Micro-batches 都跑完了,梯度累加够了,才进行一次真正的参数更新。
- 为什么要切分 Micro-batch?
这是为了解决 的效率问题。
- 不切分 (Mini-batch = Micro-batch):就像一辆大卡车(Mini-batch)要过关卡(GPU)。它太长了,必须等车头完全过了第一关,第二关才能开始工作。这导致了大量的时间浪费。
- 切分后 (使用 Micro-batch):我们将大卡车里的货卸下来,分装到 10 辆小推车(Micro-batch)上。第 1 辆小推车刚过完 GPU 0,立刻进入 GPU 1。与此同时,GPU 0 立刻开始处理第 2 辆小推车。这就形成了流水线(Pipeline)。如链接中所示,中间那一大块区域,所有的 GPU 都在忙碌(GPU 0 处理 时,GPU 3 正在处理 ),空泡(Bubble)被大大压缩。
数据并行DP
详细讲解见https://zhuanlan.zhihu.com/p/617133971与https://zhuanlan.zhihu.com/p/618865052
基于参数服务器(Parameter Server)架构的异步数据并行
其核心思想是允许 Worker 不阻塞等待最新权重,而是利用旧参数直接计算下一轮数据(实现计算与通讯重叠)以最大化利用率,并通过**受限延迟(Bounded Delay)机制限制参数滞后的步数(可以指定步数,也可以不指定步数)**来兼顾模型的收敛性。
分布式数据并行(DDP)
核心思想为Ring-AllReduce,将数据切分到若干张GPU上,使用Ring-AllReduce实现通讯量均衡分布到每块GPU上,且不受GPU个数影响。 详见链接https://zhuanlan.zhihu.com/p/504957661
DeepSpeed ZeRO
ZeRO的思想就是用通讯换显存。详解https://zhuanlan.zhihu.com/p/618865052
FP32,FP16和BF16
计算机存储浮点数遵循 IEEE 754 标准(BF16 为 Google 定制标准),通常由三部分组成:
- S (Sign):符号位,决定正负(1 bit)。
- E (Exponent):指数位,决定数据的动态范围(Range),即能表示多大或多小的数。
- M (Mantissa/Fraction):尾数位/精度位,决定数据的精度(Precision),即数字的分辨率。
我们可以把 32位 和 16位 的空间想象成有限的“停车位”,区别在于怎么分配给“范围”和“精度”。
[ FP32 (单精度, 32-bit) ] - 传统的“黄金标准”
+---+--------------------------+-----------------------------------------------------------------------+
| S | Exponent (8 bits) | Mantissa (23 bits) |
+---+--------------------------+-----------------------------------------------------------------------+
| 1 | [ ][ ][ ][ ][ ][ ][ ][ ] | [ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ] |
+---+--------------------------+-----------------------------------------------------------------------+
└-> 范围很大,精度很高,但占内存大,计算慢。
[ FP16 (半精度, 16-bit) ] - 传统的“加速方案”
+---+----------------+----------------------------------+
| S | Exponent (5) | Mantissa (10 bits) |
+---+----------------+----------------------------------+
| 1 | [ ][ ][ ][ ][ ]| [ ][ ][ ][ ][ ][ ][ ][ ][ ][ ] |
+---+----------------+----------------------------------+
└-> 范围被严重压缩(指数位太少),容易上溢/下溢。
[ BF16 (Brain Float, 16-bit) ] - 专为“大模型”设计
+---+--------------------------+-----------------------+
| S | Exponent (8 bits) | Mantissa (7 bits) |
+---+--------------------------+-----------------------+
| 1 | [ ][ ][ ][ ][ ][ ][ ][ ] | [ ][ ][ ][ ][ ][ ][ ] |
+---+--------------------------+-----------------------+
└-> ⭐️重点:指数位和FP32完全一样(8位)!
虽然精度低,但范围和FP32一样大,极其适合深度学习。| 特性 | FP32 | FP16 | BF16 |
|---|---|---|---|
| 总位数 | 32 bits | 16 bits | 16 bits |
| 指数位 (Exponent) | 8 bits (范围大) | 5 bits (范围窄) | 8 bits (范围大) |
| 尾数位 (Mantissa) | 23 bits (高精) | 10 bits (中精) | 7 bits (低精) |
| 数值范围 | |||
| 显存占用 | 100% (基准) | 50% | 50% |
| 大模型适用性 | 仅用于主权重备份 | 需要 Loss Scaling,易崩溃 | 首选,稳定且快 |
Adam优化器中的Momentum和Variance
在 Adam (Adaptive Moment Estimation) 优化器中,Momentum(动量) 和 Variance(方差,实为二阶矩) 是其两个核心组件,分别对应统计学中的 一阶矩(均值) 和 二阶矩(未中心化的方差)。
- Momentum(动量)—— 一阶矩估计 ()
对应:梯度的指数加权移动平均 (Exponential Moving Average of Gradients)
它的作用:决定更新的“方向”
Momentum 的核心思想是惯性。它模拟了一个物理过程:当一个小球滚下山坡时,它不仅受当前的重力(当前梯度)影响,还拥有之前的速度(历史梯度)。
- 数学公式:
- :当前时刻的梯度。
- :上一时刻积累的动量。
- :衰减系数(通常设为 0.9)。
- 直观解释:
- 平滑震荡:如果梯度忽左忽右(例如在峡谷地形),Momentum 会通过平均历史梯度来抵消这些震荡,让更新方向更直、更稳。
- 加速收敛:如果连续几次梯度方向相同,Momentum 会累积这个趋势,让参数更新得更快(像车子加速一样)。
- Variance(方差/二阶矩)—— 二阶矩估计 ()
对应:梯度平方的指数加权移动平均 (Exponential Moving Average of Squared Gradients)
它的作用:自适应调整更新的“步长”
这里的“Variance”在数学上更准确地说是非中心化的二阶原点矩(即 )。它衡量的是梯度的大小(Magnitude)或波动程度。
- 数学公式:
- :当前梯度的平方(element-wise)。
- :衰减系数(通常设为 0.999)。
- 直观解释:
- 自适应学习率:这是 Adam 区别于 SGD 的关键。
- 归一化(Normalization):在最终更新参数时,Adam 会把梯度除以 (即梯度的均方根)。
- 如果某个参数的梯度一直很大(陡峭), 就大,除以一个大数 步长自动变小(防止震荡)。
- 如果某个参数的梯度一直很小(平坦/稀疏), 就小,除以一个小数 步长自动变大(加速逃离平坦区)。
- 总结:两者如何配合?
Adam 的最终参数更新公式将两者结合了起来:
- 分子 (Momentum):告诉参数该往哪个方向走(结合了当下和历史的趋势)。
- 分母 (Variance):告诉参数该走多远(根据地形的陡峭程度对步长进行缩放)。
简单比喻
把训练模型比作开车下山:
- Momentum 是惯性:即使当前路稍微有点坑洼,因为你之前有速度,车子还是会顺着大方向冲下去,不会被小坑洼卡住。
- Variance 是路况适应系统:
- 如果路面非常颠簸陡峭(梯度大,Variance 大),系统自动调硬避震、减慢速度,以防翻车(步长变小)。
- 如果路面平坦开阔(梯度小,Variance 小),系统自动加速,快速通过(步长变大)。
这就是为什么 Adam 在大模型训练中如此常用,因为它既有方向感(Momentum),又能根据每个参数的情况自我调节快慢(Variance)。
堆栈图详解(2卡zero1的toy example)
结构分析
在混合精度训练(Mixed Precision Training)配合 ZeRO-1 的场景下,显存被严格分成了几个部分:
- 灰色底座:
fp16 完整的 weight(Model Parameters)
- 含义:这是模型的主干参数,用于前向传播(Forward)和反向传播(Backward)。
- 为什么是完整的?:这是 ZeRO-1 的特征。ZeRO-1 只切分优化器状态,而不切分模型参数。因此,每张 GPU 上都必须保留一份完整的 FP16 模型副本,以便独立进行计算。
- 状态:它在整个训练过程中一直存在,不随 Step 变化(除了初始化时),所以表现为底部的灰色基座。
- 橙色层:
fp32 切块的 weight(Master Weights)
- 含义:这是为了保证精度,保存在优化器(Optimizer)中的 FP32 权重副本。
- 为什么是切块的?:这是 ZeRO-1 的核心优化点。 被平均切分到了 K 个 GPU 上(这里K=2)。当前 GPU 只负责维护和更新它那 的一部分 FP32 权重。
- detach() 的含义:图注提到它
detach了。这意味着这部分显存不参与计算图的构建(不求导),它只是一个“备份仓库”,用来在 update 阶段接受梯度并更新,然后生成新的 FP16 权重。
- 绿色与粉色层:
Adam 动量 1 & 2(Optimizer States: Momentum & Variance)
- 含义:对应 Adam 优化器中的Momentum和Variance。它们也是 FP32 精度的。
- 特征:在图中,这两块颜色是后来才出现的(Step 4 之后)。这对应了 PyTorch Optimizer 的实现机制(见下文详解)。
时间轴波动与细节:为什么会有这种形状?
图中明显的“台阶式上升”和“毛刺状波动”揭示了大模型训练中的两个关键机制:Lazy Initialization(延迟初始化) 和 Gradient Accumulation/Check(梯度检查)。
- 为什么前 3 个 Step 显存较低(缺了两块颜色)?
- 现象:图中左侧,只有灰色(FP16参数)和橙色(FP32参数),缺少绿色和粉色。
- 原因:梯度更新失败(Unsuccessful Update)。
- 在混合精度训练中,通常会使用 Loss Scaler。如果前几轮迭代(Warm-up阶段)梯度的数值溢出(Inf)或者出现非法值(NaN),Scaler 会检测到并跳过该 Step 的参数更新(
optimizer.step()被跳过)。 - Lazy Initialization:PyTorch 的
torch.optim.Adam通常不会在定义时就分配动量(Momentum/Variance)的显存,而是在第一次成功执行step()时才分配。 - 结论:因为前 3 步梯度有问题,优化器没干活,所以也没申请动量显存,导致显存占用较低。
- 在混合精度训练中,通常会使用 Loss Scaler。如果前几轮迭代(Warm-up阶段)梯度的数值溢出(Inf)或者出现非法值(NaN),Scaler 会检测到并跳过该 Step 的参数更新(
- 为什么第 4 个 Step 突然“跳变”?
- 现象:显存突然上了一个台阶,绿色和粉色块出现并常驻。
- 原因:第一次成功更新(First Successful Step)。
- 第 4 步梯度正常(没有 NaN/Inf),Loss Scaler 允许更新。
- 执行
optimizer.step()。 - Adam 优化器发现
state字典是空的,于是触发初始化,申请了Momentum和Variance的显存 buffer。 - 由于是 ZeRO-1,这些状态也是切分存储的(只存 ),但依然占据了显著的空间。
- 那些尖锐的“毛刺”(Spikes)是什么?
虽然在图中主要关注的是色块的堆叠,但在色块之上通常会有动态的显存波动(图中细微的起伏或未画出的激活值):
- Activation Memory(激活值):在 Forward 过程中,我们需要保存中间层的输出用于 Backward 求导。这部分显存会随着层数的推进而线性增长,Backward 结束后释放。这通常表现为锯齿状的波峰。
- Temporary Buffers:
- Gradients:在 Backward 计算出的梯度。
- Communication Buffers:在做
All-Gather(把更新好的权重从 拼成完整的 FP16)时需要的临时空间。这是all-gather产生的临时开销。
Megatron-张量并行TP
详细讲解见https://zhuanlan.zhihu.com/p/622212228
MLP张量并行:先列再行
Multi-head Attention张量并行:先列再行
Embedding张量并行:
交叉熵张量并行:Megatron代码实现
第一阶段:计算局部 Logits (Parallel Logits)
对应图片左侧的红色虚线框区域
- 图里画的是什么?
- 输入 (形状
b, s, h)分别乘以两块 GPU 上各自维护的“部分 Embedding 转置” 和 。 - 得到结果 和 。注意它们的形状是
(b, s, v/N),说明每个 GPU 只算出了一部分词表的打分。 - 对应的代码/逻辑:
- 这是在调用
_VocabParallelCrossEntropy之前发生的事情。 - 对应代码中的
parallel_lm_logits函数调用。 - 核心含义:把全连接层(Linear Layer)切开了,大家各算各的。
第二阶段:数值稳定性处理 (Max Subtraction)
对应图片中间靠左:Y -> e1/e2 -> e -> 计算 Y-e
- 图里画的是什么?
- 对 和 按行求 Max,得到 e1 和 e2(注意:这里的 e 代表极值元素,不是指数)。
- 通过 AllReduce 得到全局最大值 e。
- 然后有一个箭头指向 Y,意思是 Y - e。
- 对应的代码:
- Python
logits_max = torch.max(vocab_parallel_logits, dim=-1)[0]
torch.distributed.all_reduce(logits_max, op=...MAX...)
vocab_parallel_logits.sub_(logits_max...)- 核心含义:为了防止后面做 时溢出,先让所有 Logit 减去最大值。
第三阶段:两条并行线的计算 (Target & Sum-Exp)
这是图中最复杂的部分,分成了上下两条路,分别计算公式 中的减数和被减数。
路线 A(上方):找出真值对应的 Logit ()
对应图中:Y1/Y2 -> L1/L2 -> AllReduce -> L
- 图里画的是什么?
- L1 (GPU 1):你看它的格子,前两个是红色的(有值),最后一个是 0。这表示:对于第 1、2 个 Token,它们的真实单词 ID 落在 GPU 1 的管辖范围内。
- L2 (GPU 2):你看它的格子,前两个是 0,最后一个是红色的。这表示:对于第 3 个 Token,它的真实单词 ID 落在 GPU 2 的管辖范围内。
- AllReduce:把 L1和 L2 加起来,得到 L。因为 0 + x = x,所以 L 里全是完整的真值 Logit。
- 对应的代码:
- Python
# 制作 Mask,把不归我管的位置置 0
predicted_logits[target_mask] = 0.0
# AllReduce 求和
torch.distributed.all_reduce(predicted_logits, op=...SUM...)路线 B(下方):计算分母 ()
对应图中:Y1/Y2 -> e1/e2 -> AllReduce -> e
- 图里画的是什么?
- 对 Y1, Y2 做指数运算 ,然后按行求和得到 e1, e2。
- AllReduce:把 e1 和 e2 加起来,得到全局的 e。
- 对应的代码:
- Python
torch.exp(vocab_parallel_logits, out=exp_logits)
sum_exp_logits = exp_logits.sum(dim=-1)
torch.distributed.all_reduce(sum_exp_logits, op=...SUM...)- 核心含义:这就是**“拼凑分母”**。所有 GPU 分头算一部分词的指数和,最后加在一起就是总的指数和。
第四阶段:计算最终 Loss
对应图片最右侧:L, e -> LOSS
- 图里画的是什么?
- 输入是 (也就是 )和 (也就是 )。
- 公式写的是
(log(e) - L) / log(e)(注:图上的公式写得有点奇怪,可能是为了归一化或者笔误,标准公式通常是 )。 - 但在标准 Megatron 代码中,计算就是简单的减法。
- 对应的代码:
- Python
loss = torch.log(sum_exp_logits) - predicted_logits梯度裁剪
梯度裁剪(Gradient Clipping) 是一种在深度学习训练中常用的优化技巧,主要用于解决**“梯度爆炸(Gradient Exploding)”**的问题。
简单来说,它的作用是:给梯度的“大小”设一个上限。如果算出来的梯度太大,超过了这个上限,就强行把它缩小,但保持方向不变。
以下是详细的解释:
- 背景:梯度爆炸
在训练深度神经网络(特别是 RNN、LSTM 或深层 Transformer/大模型)时,反向传播会涉及连乘操作。
- 如果权重稍微大一点(比如大于 1),经过几十层的连乘,梯度值会指数级增长,变得巨大无比。
- 后果:
- 步子迈太大了:参数更新时,一下子飞出了最优解的山谷,Loss 瞬间激增(甚至变成 NaN)。
- 模型崩溃:原本训练得好好的模型,突然无法收敛。
梯度裁剪就是为了防止这种“一步登天导致摔死”的情况发生。
- 它是怎么工作的?(原理)
最常用的是 按范数裁剪 (Gradient Norm Clipping),这是目前大模型训练(如 GPT, BERT, Llama)的标准做法。
步骤如下:
- 算总长度:把所有模型参数的梯度()看作一个超长的向量,计算这个向量的 L2 范数(即向量的长度),记为 。
- 比大小:设定一个阈值(
max_norm),通常设为 1.0。 - 做缩放:
- 如果 :梯度很正常,不动它。
- 如果 :梯度太大了,按比例缩小它。
公式:
关键点:这种方法只改变梯度的模长(大小),不改变梯度的方向。这意味着模型还是朝着 Loss 下降的方向走,只是这次迈的步子变小了,更安全了。
- 梯度裁剪有什么好处?
(1) 防止梯度爆炸 (Prevent Gradient Explosion)
这是最直接的好处。它保证了无论网络多深,梯度都不会变成无穷大,从而避免 Loss 突然变成 NaN(Not a Number)或 Inf(无穷大)。
(2) 提高训练稳定性 (Training Stability)
在 Loss 地形崎岖不平(比如有悬崖峭壁)的时候,大的梯度会导致参数剧烈震荡。裁剪后,更新步伐变得平稳,模型收敛曲线会更平滑。
(3) 允许使用较大的学习率
因为有了梯度裁剪这个“安全带”,我们在设置学习率(Learning Rate)时可以稍微大胆一点,不用担心偶尔出现的一个大梯度把模型搞崩。
(4) 解决混合精度训练 (FP16) 中的溢出问题
在大模型常用的 FP16 训练中,数值范围很小。如果梯度太大,很容易超出 FP16 的表示范围。梯度裁剪可以把数值拉回安全区。
混合精度计算,全精度计算,bf16精度计算占用显存分析
混合精度计算
对于参数量为的模型,使用float16数据类型的占2bytes,显存占用为;float32数据类型占用4bytes,显存占用为。
在混合精度训练中,会使用float16的模型参数进行前向传递和后向传递,计算得到float16的梯度;在优化器更新模型参数时,会使用float32的优化器状态、float32的梯度、float32的模型参数来更新模型参数。因此,对于每个可训练模型参数,占用了的显存。
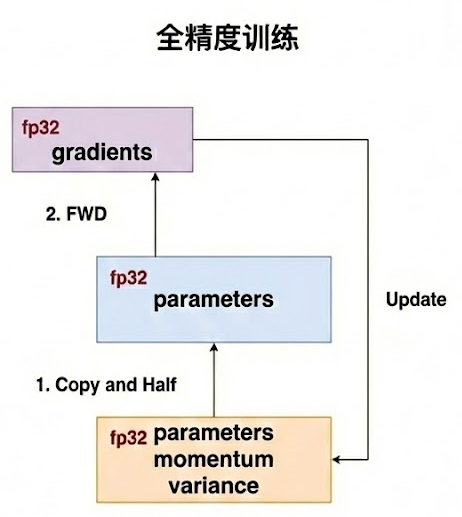
全精度计算
在全精度计算中,模型使用float32的数据类型执行全过程,占用的显存为
BF16精度计算
bf16数据类型所占用的储存为2bytes,参数量为的模型使用bf16占用的显存为。整个训练过程占用的显存为。