本博客主要介绍GRPO以及其出现后的变体的优缺点,还有对其中的设计进行一部分的分析。建议先看完之前的博客《PPO与DPO》之后再来看此博客。
GRPO 组内相对优化策略
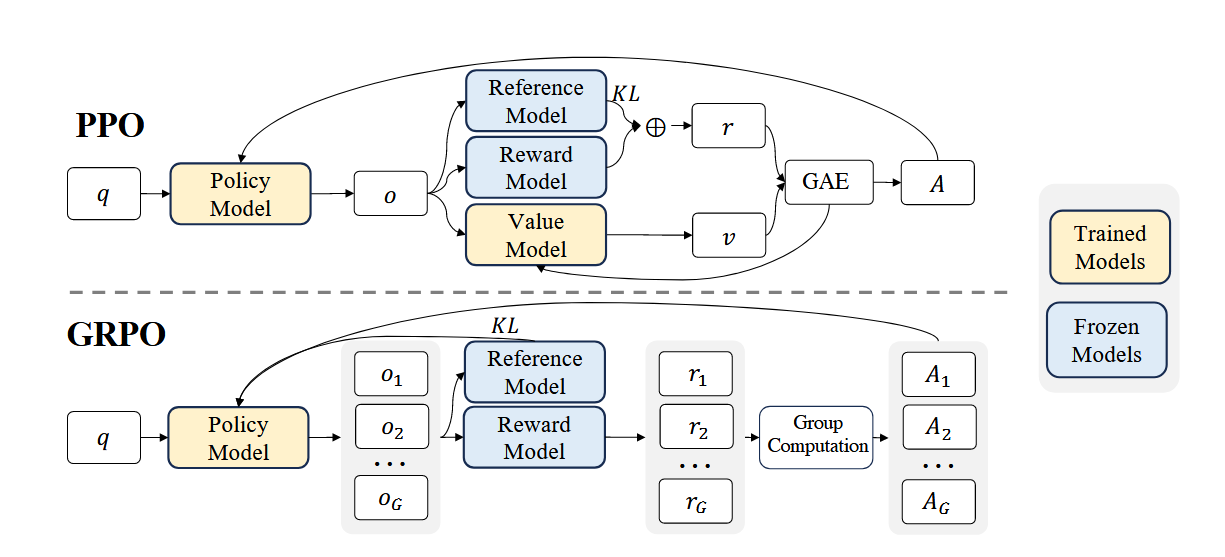
计算流程
GRPO与PPO的最大区别就是在计算优势函数 A的区别,PPO通过价值模型来计算当前的价值v,与奖励r集合GAE算法来得到优势函数A,而GRPO的计算流程为:
- 输入q,通过策略模型(LLM)来生成多个回答o1,o2,…,oG。
- 将输出的 oi输入到参考模型与奖励模型中,参考模型负责计算 oi与训练数据之间的KL散度,奖励模型则是生成每个回答的分数 r1,r2,…,rG。
- 计算这组回答分数的均值 μG和 σG。
- 计算每个样本的相对优势 Ai=σG+ϵri−μG。
这样的设计使得模型强化优势大于0的token生成,抑制优势小于0的token生成。
损失函数
JGRPO(θ)= G1i=1∑G∣Oi∣1t=1∑∣Oi∣[min(πold(oi,t∣qi,oi:<t)πθ(oi,t∣qi,oi:<t)Ait,clip(πold(oi,t∣qi,oi:<t)πθ(oi,t∣qi,oi:<t),1−ϵ,1+ϵ)Ait)−βDKL[πθ∥πref]]
这个损失函数的表达方式可能与Deepseek原论文中的表述方式有所差异,具体不同的地方在于这里面多了一个t(token)。这样做是为了更好地从代码层面理解这部分内容。这个公式中我们需要注意4个地方:
- 求和方式:
我们可以把上述损失函数公式转换为:
LGRPO-agg=G1i=1∑G∣Oi∣1t=1∑∣Oi∣Li,t
我们可以称之为这个公式为“序列平均-token平均“公式。这样做的非常适合长短样本极度不均,但短样本同等重要的场景。例如指令微调(SFT)时,模型输出一句简短的“抱歉,我不能回答”,其重要性可能等同于一篇长篇大论。但也变相放大了短句中单个 Token 的权重,缩小了长句中单个 Token 的权重,容易导致模型对短句子中的个别错误过度敏感(梯度的方差变大)。
-
重要性采样:
在 Transformer 架构中,自回归解码( Rollout)的计算开销极大。生成一个 Token 需要把所有的历史 KV Cache 过一遍。在典型的 RLHF 训练中,80% 甚至 90% 的时间都花在“让模型自己思考并生成答案”上,而真正的反向传播更新(Backprop)可能只占 10% 的时间。如果辛辛苦苦生成的数据只做一次梯度下降就扔掉,样本效率(Sample Efficiency)会极低,训练成本会突破天际。
重要性采样的引入,完美解决了“舍不得扔数据”的问题。它允许我们在不重新采样的情况下,对同一批旧数据进行多次梯度更新。加入重要性采样后我们的生成过程就变为:
- 采样阶段: 将当前模型冻结为旧策略 πθold,生成一批数据(比如 64 个回答)。
- 微步更新(Epoch 1): 使用这批数据更新模型,模型参数稍微移动,变成 πθ1。
- 数据复用(Epoch 2): 我们不扔掉刚才那 64 个回答,继续用它们训练 πθ1。
此时,正在训练的模型 πθ1 和生成数据的模型 πθold 已经不是同一个了,直接算梯度会导致方向错误。 我们计算一个重要性权重比例 πθold(o∣q)πθ1(o∣q)。如果新模型生成这个答案的概率变大了,我们就给这个梯度加个杠杆;如果变小了,我们就缩小梯度。通过这个比例修正,我们在数学上”假装”这批数据是新模型自己生成的。
- 循环: 这样可以安稳地在这个 batch 上更新 2 到 4 个 Epoch(微步),榨干这批数据的价值。
- 丢弃并重新采样: 当旧数据被复用太多次,导致新旧模型差异过大(被 Clip 强行截断过多)时,这批数据才会被废弃,重新进行 Rollout。
使用重要性采样,是为了让我们能合法、合理、在数学上正确地“白嫖”旧数据,从而在极其昂贵的大模型训练中实现“一次采样,多次更新”。
-
token级别的优势函数如何获得:
公式中出现了token级别的 $A_i^t$需要获取,为了探究如何获取我们从代码层面来寻找答案:在 GRPO 算法的工程代码实现中,模型无法获得单个 Token 的精细打分,只能得到针对整条回答的序列级标量优势 $A_i$。为了构建数学公式中所需的 Token 级优势 $A_i^t$,代码通过 `A_i.unsqueeze(-1)` 将标量升维,并利用与 `response_mask` 的乘法运算触发了张量的自动广播机制(Broadcasting),将 Shape 平滑扩展至 `(batch_size, response_length)`。这在物理意义上代表着系统放弃了对单个 Token 的独立建模,而是简单粗暴地将整条序列的总体评分无差别地“复制”并广播给内部的所有有效 Token,从而导致同一条回答内的每一个有效 Token 都共享着完全相同的优势值。
-
KL散度的具体计算方式
GRPO的代码选择了使用K3估计量来计算KL散度:
K3=πθ(oi,t∣qi,oi:<t)πref(oi,t∣qi,oi:<t)−logπθ(oi,t∣qi,oi:<t)πref(oi,t∣qi,oi:<t)−1
数学性质: 根据泰勒展开和对数不等式,无论概率比值如何变化,x−logx−1≥0 永远成立(当且仅当 x=1 时等于0)。这保证了 KL 散度的非负性,提供了一个非常稳定且低方差的无偏估计。它能极大地缓解 RL 训练初期 KL 散度震荡导致的训练崩溃。
DAPO提高裁剪上限与动态采样优化策略
损失函数
JDAPO(θ)=E(q,a)∼D,{oi}i=1G∼πθold(⋅∣q)∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵlow,1+ϵhigh)A^i,t)
s.t. 0<∣{oi∣is_equivalent(a,oi)}∣<G
我们来关注一下其改动的地方:
- 提高clip的上界
在GRPO的训练过程中,会出现熵坍塌现象。即策略熵(policy entropy)在训练初期急剧下降并持续趋近于零的现象,即在少数的训练step之后,模型对于自己的回答过于自信(策略变得过度确定, overly confident),无法生成多样化响应,从而陷入局部最优。
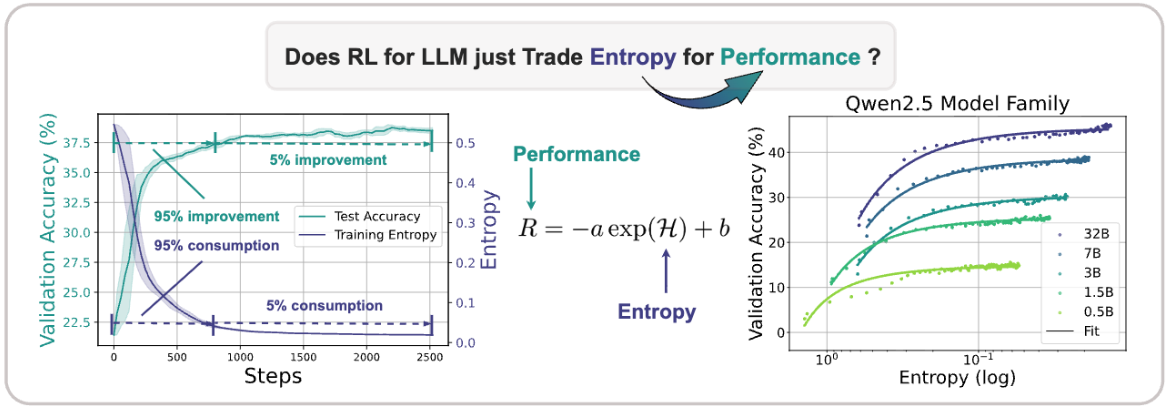
并且GRPO 中 clip 上界较小,会导致低概率但优势为正的关键 token 被抑制。比如 old policy 难得采到一个关键 token且概率极低,而当前模型对此 token 的概率很高,那么 rt 的比率就会很大,但却会因为 clip 限制过紧被裁剪,那么低概率关键 token 就几乎没有被很好的训练。
DAPO 通过放开上界保护和放大这种稀有但高价值的探索。
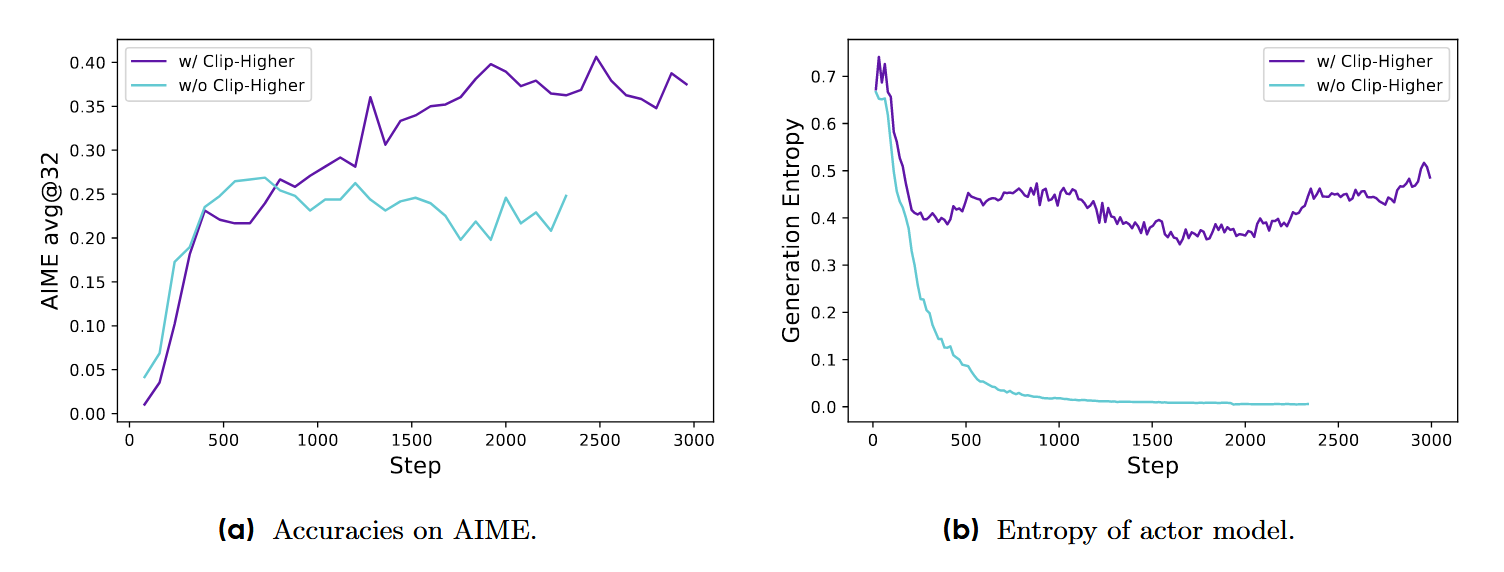
- 动态采样
GRPO 训练中,**若同一 query 被多次采样,并采样结果的得分相同,就会导致这些样本的优势为 0,进而梯度为 0,无法贡献有效的奖励训练信号。**那么实际有效的梯度就会少于采样的次数,导致最后梯度汇集时信息不足以及训练资源的浪费。而且这种效果可能随着训练的进行越来越明显,因为越到后边模型效果越好,给出高分回答的几率就越大,相对优势就越小,而且会出现很多满分的情况。所以DAPO添加了限制,就是如果采样出来的回答全是 0 或者 1 就继续采样,保证采样具有得分上的多样性:
s.t. 0<∣{oi∣is_equivalent(a,oi)}∣<G
- 求和方式
JDAPO(θ)≈∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣Li,t
Token-Level 策略梯度损失 (Token-Level Policy Gradient Loss):为了防止序列长度对优势的稀释,将GRPO目标函数中每个序列内的优势平均(分母为 ∣oi∣)替换为从是批次内所有token的平均(分母为 ∑i=1G∣oi∣),确保每个token对梯度更新的贡献是均等的,无论它来自长序列还是短序列。但这种求和方式会在算法底层机制上鼓励模型变得啰嗦,进而增加推理时的成本(Token 消耗和延迟)。所以DAPO又引入了惩罚机制
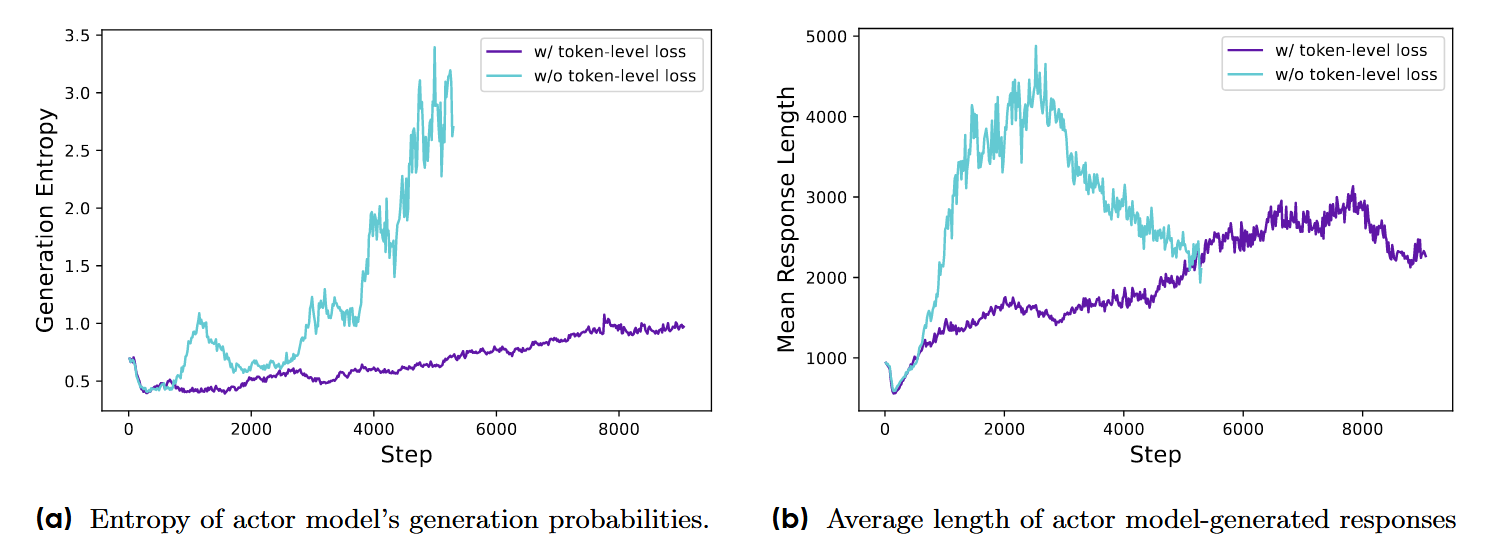
- 软惩罚机制
这里用了两个策略:
- 过长样本过滤 (Overlong Filtering):被截断的样本屏蔽其损失
- 软过长长惩罚机制 (Soft Overlong Punishment):当回答长度超过预设的最大值时,会施加一个惩罚,且惩罚力度随长度增加而变大:
Rlength(y)=⎩⎨⎧0,Lcache(Lmax−Lcache)−∣y∣,−1,∣y∣≤Lmax−LcacheLmax−Lcache<∣y∣≤LmaxLmax<∣y∣
-
移除KL散度
KL 散度的目标是避免模型行为与初始模型偏离过远,KL 惩罚项可以调节模型与冻结参考策略之间的发散程度。但在长文本推理模型中,实验发现模型分布可能会显著偏离初始模型,因此 KL 散度不再必要。
-
规则奖励机制
训练时直接设置奖励机制判断答案是否正确来获得奖励,符合要求就给1,不符合就给-1。这种方法在定理证明、编程和数学问题等多个领域得到了验证。
Dr.GRPO
动机:Dr.GRPO的动机是在Diss原始GRPO的优势估计有偏(Bias),和DAPO的Token-Level策略梯度损失动机类似但是更进一步,具体来说:
- 响应长度偏差 : 来自GRPO目标函数的响应长度 ∣oi∣ 项。
◦ 当优势 A^i,t>0(表示回答正确)时,较短回答会产生更大的梯度更新,从而让策略偏好更短的正确回答。
◦ 当优势 A^i,t<0(表示回答错误)时,较长回答因为 ∣oi∣ 较大而受到的惩罚更小,使得策略在错误回答中更偏好较长的回答。
- 问题难度偏差 : 来自GRPO优势函数的标准差 std(R(q,o1),...,R(q,oG)) 项。
◦ 标准差较低的问题(如特别简单或特别困难、几乎总是 1 或 0)会得到更大的权重,从而在策略更新中影响更大。与常见的 advantage normalization(按 batch 归一化)不同,这种按问题归一化会让不同问题在目标函数中具有差异化的权重,导致难度相关偏置。
实现:移除以上讨论的两个偏差项: 即在计算策略梯度时不除以回答长度 ∣oi∣,在计算优势时不除以奖励的标准差 std(R(q,o1),...,R(q,oG))。修正后的目标函数等价于标准的PPO目标,而优势项进一步简化:
G1i=1∑Gt=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ϵ,1+ϵ)A^i,t]}
where A^i,t=R(q,oi)−mean({R(q,o1),…,R(q,oG)})