在上一个博客中我们介绍了GRPO,DAPO与Dr.GRPO这三个变体,这篇博客我们来介绍千问提出的两个变体GSPO与SAPO
GSPO 分组序列策略优化
现有问题
在实验中PPO与GRPO却用逐词的方法来训练。PPO 和 GRPO 是对模型输出的 token 逐个优化,这种做法的本意是更精细的优化,但论文指出在大模型长文本的场景下,就容易引入噪声和奖励偏差,导致模型训练失败。 GSPO 的核心思路就是把奖励和优化目标重新对齐,从给每个 token 打分,改为直接对整个句子打分。这种切换带来的好处具体为:
一是更稳定:GSPO 直接对整句进行训练,减少了词级波动带来的训练噪声。
二是更高效:GSPO 根据句子的分筛选样本,仅保留高质量纯净的样本参与优化,让模型更快收敛,效果更好。
现有的LLM都是基于MoE进行的设计,这样做会使模型在推理时选取少量的专家模块进行激活。这样做虽然高效,但是对于RL的训练而言,有可能出现我在旧策略下激活了专家A和专家B,但是在新策略下激活了专家C和专家D。这样会导致重要性比率失真急剧上升,频发触发Clip,导致梯度失真。
损失函数
GSPO的损失函数如下:
GSPO的优势估计为:
其重要性权重是基于一句完整的话来定义的:
1. 灾难的根源:MoE 路由的“非连续性”突变 在稠密(Dense)模型中,参数更新是一点点挪动的,所以新旧模型对同一个 Token 的概率 和 通常非常接近,比值(Ratio)自然在 附近波动。 但在 MoE 模型中,引入了路由网络(Router): • 假设在旧策略 下,Token “苹果”被分配给了专家 A,算出的生成概率是 0.8。 • 更新一两步之后,路由网络的权重稍微变了一点点。对于新策略 ,Token “苹果”的分配可能瞬间跳变到了专家 B。由于专家 B 之前没怎么学过这个词,算出的概率可能瞬间暴跌到 0.01。 • 致命比率: 此时,对于这单个 Token,它的重要性采样比率瞬间变成了 。
2. 传统 GRPO/PPO 的绝望(Token 级别裁剪) 在传统的 GRPO 中,Clip 函数是包裹在每一个 Token 外面的。 因为 MoE 的路由切换非常频繁,一条 1000 个 Token 的句子里,可能随时有几十个 Token 发生了“专家跳变”。 这导致大量的 Token 级别的比率瞬间飙升到 2.0 甚至 10.0,或者暴跌到 0.01。 这样导致它们会立刻撞上 的两面墙(比如 0.8 到 1.2)。一旦被 Clip,这个 Token 的梯度就变成了 0。GPU 吭哧吭哧算了一整圈,结果大部分 Token 全被裁剪了,有效更新极其微弱,模型彻底“僵死”。
3. GSPO 的“求和平均”充当“减震器” 现在,我们再回头看刚才提取的 GSPO 那个长长的公式。 它是先在整句范围内把所有 Token 的对数概率差(log-probs difference)加起来求平均,然后再做指数还原,最后才去进行 Clip 裁剪。
• **削峰填谷(Cancellation Effect):** 在一条 1000 个 Token 的回答中,虽然有几个 Token 因为专家切换导致概率暴跌($\log$ 差值为极大的负数),但大概率也会有另外几个 Token 因为切到了更合适的专家而概率暴涨($\log$ 差值为极大的正数)。而剩下 900 多个没有切专家的 Token,它们的差值几乎为 $0$。
• **宏观维稳:** 当你把这 1000 个数值加起来求平均时,局部的“剧烈抖动”被极其庞大的序列长度(分母 $|y_i|$)强行稀释和相互抵消了。
• **最终结果:** 算出来的序列级比率 $s_i(\theta)$ 依然会稳如泰山地停留在 $1.05$ 或 $0.98$ 这样极小波动的安全区间。SAPO
核心问题
SAPO 的核心动机直指大模型 RL 训练(尤其是使用 MoE 架构时)中一个致命的工程与数学痛点:Token 级重要性采样比率的高方差与“硬裁剪(Hard Clipping)”的脆弱性。
- 重要性比率方差爆炸(尤其在 MoE 中): 在长文本生成或 MoE(混合专家)模型中,由于专家路由的异质性,不同 Token 的重要性比率(当前策略概率与旧策略概率的比值)会出现极大的波动 。
- “硬裁剪(Hard Clipping)”的两难困境: GRPO 和 GSPO 等现有算法都依赖硬裁剪(即将超出 范围的梯度直接强制归零)来限制这种方差 。但这带来了一个无法调和的矛盾:
- 如果裁剪范围设置得太紧,大量样本的梯度直接被丢弃,导致有效训练样本严重不足(Sample Efficiency 极低) 。
- 如果裁剪范围设置得太松,又会引入大量来自偏离策略(Off-policy)样本的噪声梯度,导致模型更新极不稳定,甚至崩溃 。
核心设计
一、温度控制的平滑软门控
SAPO 用一个形如 Sigmoid 的平滑衰减函数 替换了原本的 函数 。
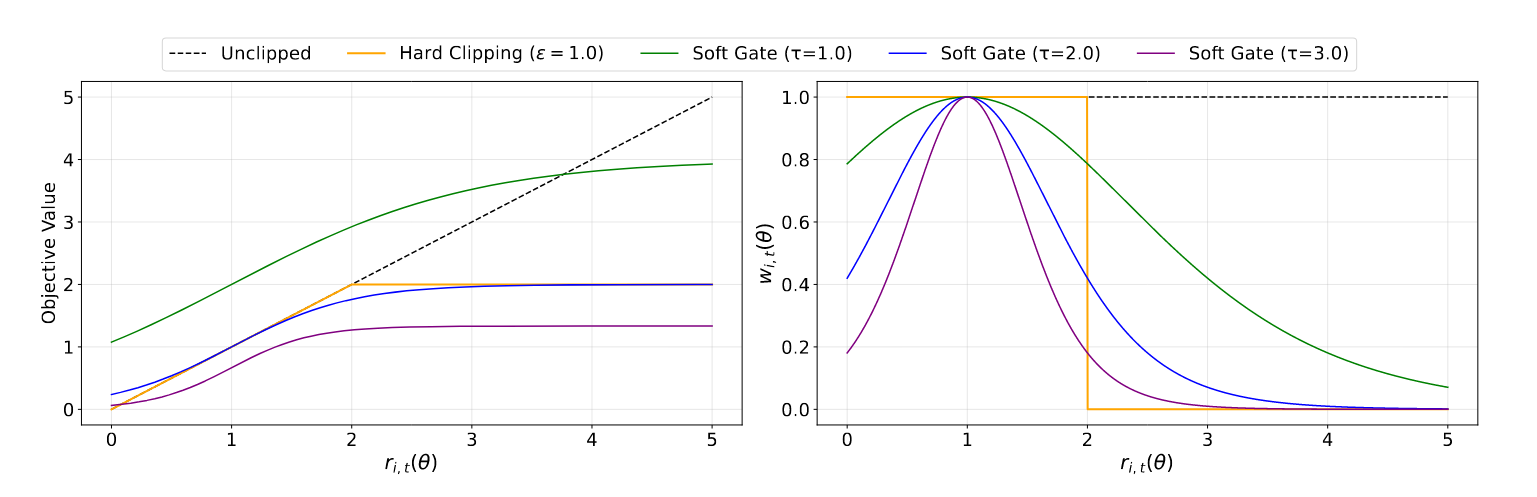
这样做有如下好处:
- 它构建了一个连续的信任区域(Continuous Trust Region) 。
- 当 Token 的生成概率接近旧策略(即比率在 1 附近)时,梯度被完整保留,鼓励模型进行有效的更新和探索 。
- 当概率比率开始发生偏离时,梯度权重会随着偏差的增大呈指数级平滑衰减,有效抑制了极端 Off-policy 样本带来的优化噪声,又不像硬裁剪那样彻底丢失信号 。
二、非对称温度控制
这是 SAPO 中一个极具洞察力的创新。SAPO 为“正优势(做对的 Token)”和“负优势(做错的 Token)”设置了不同的温度参数 和 ,并且强制要求 。
- 背后的物理意义: 论文通过分析 Logits 梯度发现,正向更新只会提高单个正确 Token 的概率,而负向更新(惩罚)会同时抬高词表中成千上万个不相关 Token 的概率 。在数十万词表的大模型中,负向梯度的弥散极其容易引发训练失稳(Instability)。
- 解决方案: 给予负向 Token 更高的温度参数 ,意味着当模型生成错误的 Token 且发生分布偏移时,SAPO 会让其梯度以更快的速度衰减 。实验证明,这种“非对称”设计极大地降低了模型早期崩溃(Early collapse)的风险,是维持训练稳定的关键 。